




Add multiple libraries using the CSV template upload
Assign one or multiple libraries to a pool
CSV upload will automatically create a pool
This step is required for your run to be scheduled
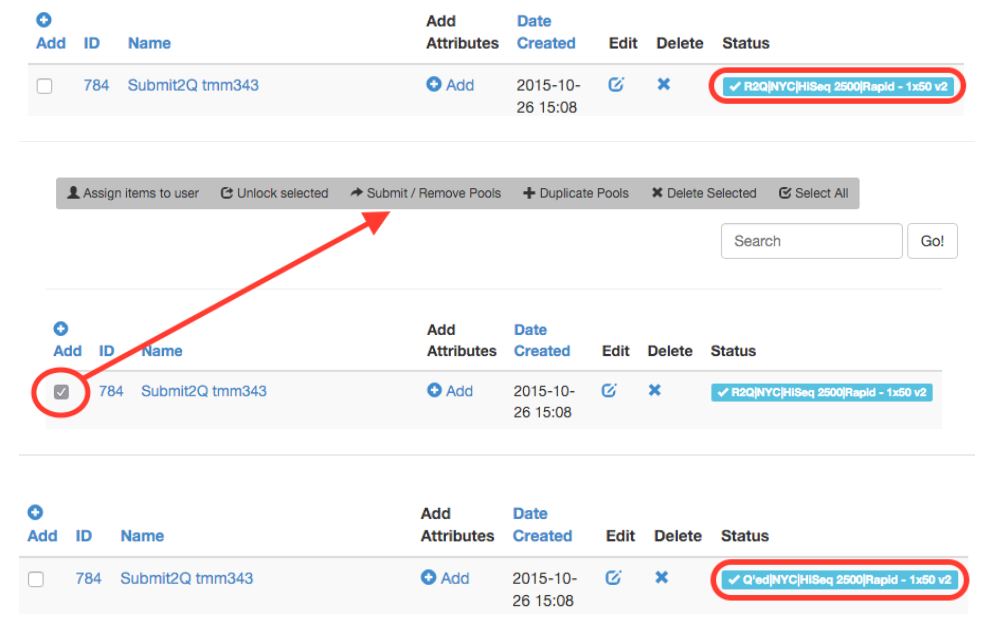
Pool status will change from “R2Q” to “Q’ed”, as seen below (click to enlarge):
The GenCore manager will send an email confirmation that includes the submission deadline and scheduled run date
Quantify libraries using the KAPA protocol within 5 days of your scheduled run date
Do not freeze/thaw the pool after doing KAPA
Add final concentration and volume of pool by clicking on the pool name and then “Add Vol & Conc”
Place on the “Sequencing Submissions” rack in 4°C fridge
Provide the TapeStation results for your final pool by replying to the confirmation email
