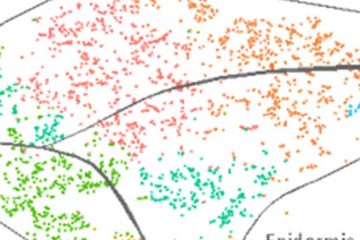
Bioinformatics
Nextflow & nf-core on NYU HPC
All nextflow and nf-core pipelines have been successfully configured for use on the HPC Cluster at New York University. The configuration applies required and recommended options in order to have efficient and reliable nextflow runs. Below is the NYU HPC configuration and the latest version can always be found at Read more